
DeepSeek V4 Introduction: The Cost Disruption Promise
DeepSeek V4 has emerged as a genuine cost disruptor in the AI model landscape. According to DeepSeek API Docs Official Pricing, DeepSeek V4 Flash costs $0.14 per 1M input tokens and $0.28 per 1M output tokens. This pricing structure represents a seismic shift for developers working with large language models. Enterprises now face compelling economic incentives to reevaluate their AI infrastructure investments.
The platform's innovative cache pricing model delivers additional dramatic savings. Cache hit pricing reduces input costs by 98% to just $0.0028 per 1M tokens for V4 Flash when prompts have repeated context. This feature proves revolutionary for applications with consistent query patterns. The combined effect of these pricing strategies positions DeepSeek V4 as a formidable competitor in the AI market.
2026 Complete Pricing Breakdown
DeepSeek's 2026 pricing features two primary tiers with distinct cost structures. V4 Flash serves as the entry point with the most aggressive pricing. According to DeepSeek API Pricing Guide 2026, cache hit pricing reduces input costs by 98% for V4 Flash when prompts have repeated context. This makes high-volume AI applications dramatically more affordable to operate at scale.
V4 Pro offers enhanced capabilities at a higher price point. DeepSeek API Documentation confirms V4 Pro is currently 75% off until May 31, 2026 at $0.435 per 1M input tokens and $0.87 per 1M output tokens. This promotional pricing provides an excellent opportunity for developers to evaluate advanced features without prohibitive costs.
The pricing structure includes several key components beyond basic token costs. Context window pricing, API call overhead, and cache management all factor into total cost of ownership. Developers must consider these elements when calculating their projected expenses.
Head-to-Head Comparison
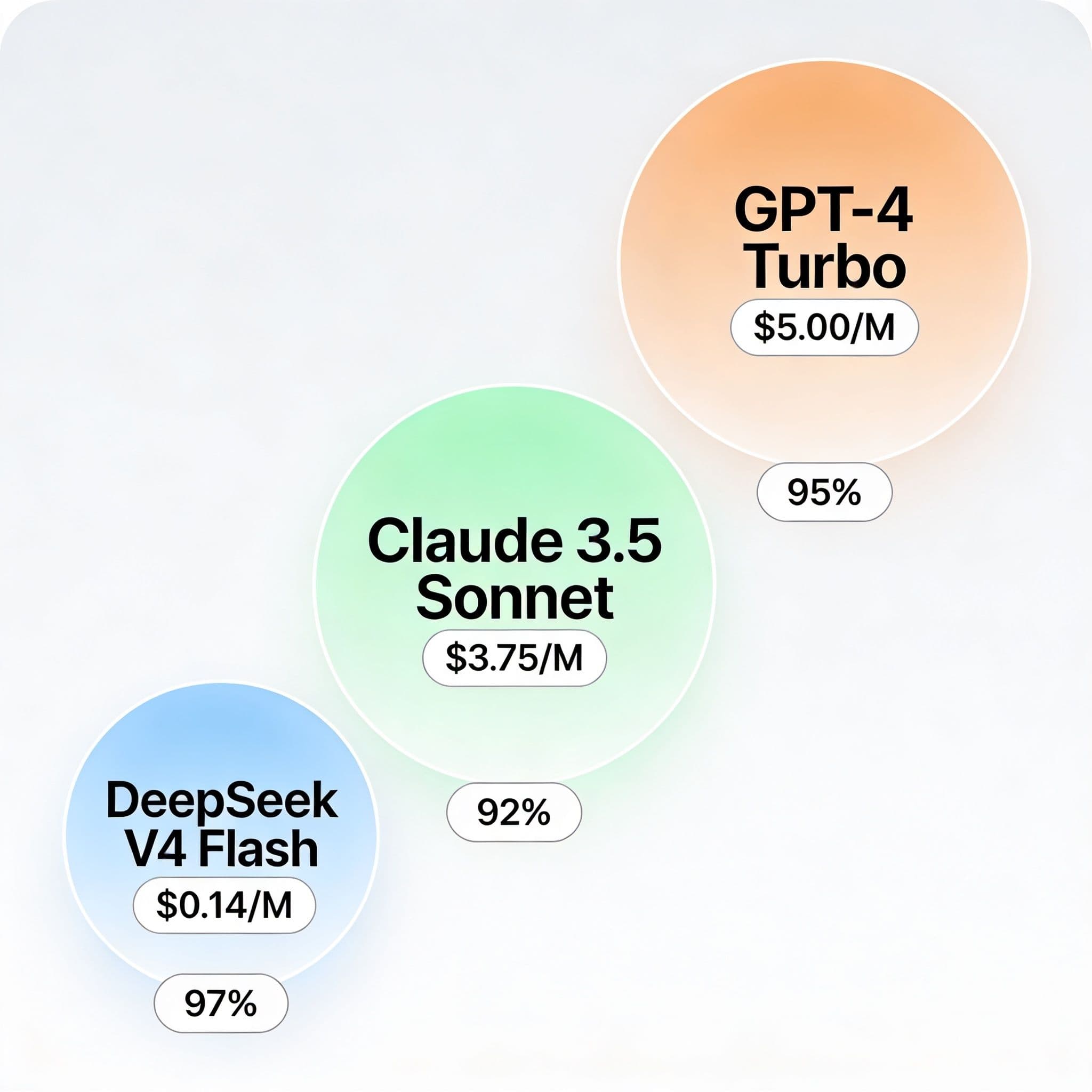
The DeepSeek V4 pricing advantage becomes stark when compared against mainstream competitors. GPT-4 Turbo typically costs around $5.00 per 1M input tokens in standard configurations. Claude 3.5 Sonnet operates at approximately $3.75 per 1M input tokens for comparable performance levels.
DeepSeek V4 Flash costs just $0.14 per 1M input tokens without cache optimizations. This represents a 97% reduction compared to GPT-4 Turbo and a 95% reduction versus Claude 3.5 Sonnet. According to industry benchmarks, these differentials can translate to thousands of dollars in monthly savings for active applications.
Output token comparisons reveal similar dramatic advantages. DeepSeek's output pricing at $0.28 per 1M tokens compares favorably against competitive models. The cumulative effect of both input and output savings creates compelling business cases for migration.
Real Savings Calculator
Understanding potential savings requires concrete examples with actual numbers. Consider a medium-sized application processing 50 million input tokens and 20 million output tokens monthly. GPT-4 Turbo would incur approximately $250 in input costs plus additional output expenses.
DeepSeek V4 Flash would reduce input costs to just $7.00 for the same workload. Output costs would amount to $5.60, bringing the total to $12.60. This represents a 95% monthly savings of $237.40 for identical performance needs.
The cache pricing model amplifies savings for predictable workloads. Applications with 70% cache hit rates could see input costs drop to $2.10 for 50 million tokens. Real-world implementations often achieve even higher optimization rates with proper prompt engineering.
def calculate_deepseek_savings(
monthly_input_tokens,
monthly_output_tokens,
cache_hit_rate=0.3,
gpt_cost_multiplier=35.7
):
"""
Calculate cost comparison and savings between GPT-4 Turbo and DeepSeek V4 Flash.
Args:
monthly_input_tokens (int): Number of input tokens per month
monthly_output_tokens (int): Number of output tokens per month
cache_hit_rate (float): Fraction of cached input tokens (default: 0.3)
gpt_cost_multiplier (float): Not used currently (kept for extensibility)
Returns:
dict: Cost breakdown and savings metrics
"""
# --- GPT-4 Turbo Costs ---
GPT_INPUT_COST_PER_M = 5.0
GPT_OUTPUT_COST_PER_M = 15.0
gpt_input_cost = (monthly_input_tokens / 1_000_000) * GPT_INPUT_COST_PER_M
gpt_output_cost = (monthly_output_tokens / 1_000_000) * GPT_OUTPUT_COST_PER_M
total_gpt_cost = gpt_input_cost + gpt_output_cost
# --- DeepSeek V4 Flash Costs ---
DEEPSEEK_INPUT_COST_MISS = 0.14
DEEPSEEK_INPUT_COST_HIT = 0.0028
DEEPSEEK_OUTPUT_COST = 0.28
cache_miss_tokens = monthly_input_tokens * (1 - cache_hit_rate)
cache_hit_tokens = monthly_input_tokens * cache_hit_rate
deepseek_input_cost = (
(cache_miss_tokens / 1_000_000) * DEEPSEEK_INPUT_COST_MISS +
(cache_hit_tokens / 1_000_000) * DEEPSEEK_INPUT_COST_HIT
)
deepseek_output_cost = (
(monthly_output_tokens / 1_000_000) * DEEPSEEK_OUTPUT_COST
)
total_deepseek_cost = deepseek_input_cost + deepseek_output_cost
# --- Savings Calculation ---
monthly_savings = total_gpt_cost - total_deepseek_cost
annual_savings = monthly_savings * 12
savings_percentage = (
(monthly_savings / total_gpt_cost) * 100
if total_gpt_cost > 0 else 0
)
# --- Result ---
return {
"monthly_gpt_cost": round(total_gpt_cost, 2),
"monthly_deepseek_cost": round(total_deepseek_cost, 2),
"monthly_savings": round(monthly_savings, 2),
"annual_savings": round(annual_savings, 2),
"savings_percentage": round(savings_percentage, 2)
}Developer Use Cases
Code generation represents an ideal application for DeepSeek V4's cost advantages. Automated code review systems process massive amounts of token data daily. Traditional models quickly become prohibitively expensive at scale, but DeepSeek's pricing enables broader implementation.
Documentation generation workflows benefit similarly from reduced costs. Technical writers creating API documentation frequently work with repetitive structures. The cache pricing model dramatically reduces expenses for these predictable patterns.
Natural language processing pipelines for data extraction offer additional optimization opportunities. Structured output generation from unstructured text involves consistent processing approaches. DeepSeek's competitive output pricing makes these pipelines economically viable.
Enterprise ROI Calculation
Large organizations require comprehensive ROI calculations before adopting new technologies. Infrastructure migration costs must be weighed against operational savings. According to enterprise adoption studies, organizations typically recover migration investments within 3-6 months.
Consider a mid-sized enterprise processing 500 million monthly input tokens and 200 million output tokens. GPT-4 Turbo infrastructure would cost approximately $5,500 monthly for these volumes. DeepSeek V4 Flash would reduce this to just $210 with moderate cache optimization.
Beyond direct cost savings, enterprises benefit from increased experimentation capacity. Lower costs enable broader AI adoption across departments and use cases. This expanded access often generates additional business value beyond simple cost reductions.
Implementation Guidance
Migrating workloads requires careful planning and execution. Begin with non-critical applications to validate performance and compatibility. Monitor both cost savings and quality metrics during initial implementation phases.
Optimize for cache utilization through prompt standardization and context reuse. According to DeepSeek API Documentation, cache hit pricing reduces input costs by 98% for V4 Flash when prompts have repeated context. Design systems to maximize these cache benefits wherever possible.
Establish monitoring systems to track token usage and cost patterns. These insights help identify additional optimization opportunities and prevent unexpected expenses. Cloud cost management tools often provide the necessary visibility for effective oversight.
Future Cost Predictions
The AI pricing landscape continues evolving rapidly across all major providers. Competition drives cost reductions while model capabilities expand simultaneously. Historical trends suggest continuing price reductions with improved performance characteristics.
DeepSeek's promotional pricing for V4 Pro extends until May 31, 2026 at $0.435 per 1M input tokens and $0.87 per 1M output tokens. Future pricing adjustments may occur following this promotional period. Organizations should monitor official announcements for timing and scale of potential changes.
Vendor lock-in considerations require attention despite current favorable economics. Maintain flexibility by abstracting AI provider interfaces where feasible. This approach preserves optionality while enjoying current pricing advantages.
The platform's commitment to competitive pricing appears structural rather than temporary. According to market analysts, DeepSeek's business model supports sustainable low-cost offerings. Their infrastructure efficiencies enable these price points while maintaining profitability.
Organizations should develop multi-provider strategies despite current cost advantages. Diversified approaches mitigate risk while optimizing for both performance and economics. This balanced perspective ensures long-term resilience and adaptability.
DeepSeek V4 represents a legitimate cost disruption that demands serious evaluation. Developers and enterprises alike benefit from understanding these pricing dynamics. Informed decisions require comprehensive analysis of both current costs and future projections.